Otimização de Custos de Plano de Saúde#
1. Entendimento do Negócio#
1.1 Contexto de negócio#
Uma empresa do ramo alimentício tem mais de 20 mil colaboradores em todo o Brasil. Com o passar dos anos a empresa percebeu um aumento no custo do plano de saúde com seus colaboradores. Como forma de entender esse comportamento, a gerência de Benefícios e Bem Estar da Diretoria de Pessoas conduziu uma pesquisa interna com um grupo de 1.338 colaboradores sorteados aleatoriamente.
A gerência acredita que fatores como fumo e obesidade podem estar relacionados com o maior uso do plano de saúde, o que acaba elevando os custos. Portanto, os colaboradores da pesquisa responderam características pessoais como o Índice de Massa Corpórea (IMC), Qte de Filhos e se fazem uso de cigarros.
1.2 Objetivo#
O objetivo deste projeto é compreender o cenário e os desafios enfrentados pela empresa no que diz respeito ao aumento no custos do plano de saúde de seus colaboradores. Para tanto, serão identificados os principais fatores que contribuem para os altos custos, as oportunidades de melhoria e as possíveis ações preventivas que podem ser tomadas pela gerência.
1.3 Premissas#
Para a execução da análise, levou-se em consideração as seguintes premissas:
Os dados fornecidos pela empresa são precisos e representam adequadamente a situação atual dos custos do plano de saúde.
A coleta e a limpeza dos dados foram realizadas de maneira adequada, estando isentas de possíveis problemas associados a riscos operacionais, imparcialidade ou tendências.
A empresa está aberta à implementação de mudanças com base nas descobertas deste projeto.
A análise considerará apenas os fatores internos da empresa, excluindo influências externas não controláveis.
1.4 Riscos Envolvidos#
Análise SWOT#
| Matriz SWOT | ||
|---|---|---|
| Fatores internos (estão em nosso controle) | Forças | Fraquezas |
|
|
|
| Fatores externos (não estão em nosso controle) | Oportunidades | Ameaças |
|
|
|
1.5 Custos x Benefícios#
Os custos associados a este projeto incluem o tempo e os recursos dedicados à coleta, limpeza e análise dos dados, bem como a implementação de quaisquer mudanças recomendadas.
Os benefícios esperados incluem uma redução nos custos do plano de saúde, uma melhoria na saúde geral dos colaboradores e uma melhor compreensão dos fatores que influenciam os custos.
1.6 Critérios de Sucesso#
Identificação clara dos principais fatores que influenciam os custos do plano de saúde.
Desenvolvimento de ações preventivas viáveis e eficazes para reduzir os custos empregando a metodologia 5W2H.
Aceitação e implementação bem-sucedida das mudanças propostas pela empresa.
Melhoria mensurável nos custos do plano de saúde e na saúde geral dos colaboradores ao longo do tempo.
1.7 Resultados#
Os principais resultados esperados incluem:
Identificação e quantificação dos principais fatores correlacionados com os custos do plano de saúde na empresa.
Formulação de recomendações de ações preventivas que a empresa pode adotar para reduzir esses custos.
Avaliação e projeção do impacto potencial de alterações nos fatores de risco sobre os custos com saúde.
1.8 Recursos#
1.9 Planejamento do projeto#
O projeto segue a metodologia CRISP-DM, uma consolidação das melhores práticas na área de dados, conhecida como Cross Industry Standard Process for Data Mining, visando aumentar suas chances de sucesso.
Proposta de solução: A análise será dividida em três partes principais:
Parte 1: Análise Exploratória de Dados (AED): Exploração dos dados disponíveis para verificar a qualidade dos dados, identificar padrões, tendências e insights iniciais.
Parte 2: Análise de Correlação e Solução do Problema: Análise da relação entre as variáveis verificando o comportamento conjunto e investigando potenciais relações causais para o custo do plano de saúde da empresa.
Parte 3: Modelagem Inferencial: Desenvolvimento e ajuste de um modelo de Regressão Linear Múltipla para entender como cada variável explica o custo de saúde.
Perguntas a serem respondidas:
Quais fatores estão mais relacionados com o Custo do Plano de Saúde na empresa?
Que tipo de ações preventivas a empresa pode fazer de forma a diminuir esse custo?
Hipóteses a serem testadas:
H1: O fumo e a obesidade estão relacionados com o maior uso do plano de saúde, o que acaba elevando os custos.
H2: Quanto maior a quantidade de filhos maior será o número de dependentes no plano de saúde, o que eleva os custos.
2. Entendimento do Dados#
2.1 Descrição dos dados#
2.1.1 Importações#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import display
import locale
# Pacotes de modelagem
import statsmodels as sms
import statsmodels.api as sm
from scipy import stats
# Definir a formatação local para o Brasil
locale.setlocale(locale.LC_ALL, 'pt_BR.UTF-8')
# Definir um alias para a função locale.currency()
def moeda(valor):
return locale.currency(valor, grouping=True)
# Configurando o pandas para exibir todo o conteúdo de uma célula, sem truncar o texto
pd.set_option('display.max_colwidth', None)
2.1.2 Lendo o arquivo de dados#
xlsx = './data/base_plano_de_saude.xlsx'
nomes_abas = ['base', 'Metadados']
dfs = pd.read_excel(xlsx, sheet_name=nomes_abas)
base = dfs['base']
Metadados = dfs['Metadados']
Informações básicas sobre o DataFrame:
base.head()
| Idade | Sexo | IMC | Qte_Filhos | Fumante | Região | Custo_Saude | |
|---|---|---|---|---|---|---|---|
| 0 | 19 | Feminino | 27.900 | 0 | Sim | Centro | 1688.492400 |
| 1 | 18 | Masculino | 33.770 | 1 | Não | Sudeste | 172.555230 |
| 2 | 28 | Masculino | 33.000 | 3 | Não | Sudeste | 444.946200 |
| 3 | 33 | Masculino | 22.705 | 0 | Não | Norte | 2198.447061 |
| 4 | 32 | Masculino | 28.880 | 0 | Não | Norte | 386.685520 |
Metadados
| Variável | Descrição | |
|---|---|---|
| 0 | Idade | Idade do colaborador |
| 1 | Sexo | Sexo do colaborador |
| 2 | IMC | Índice de Massa Corporal do colaborador |
| 3 | Qte_Filhos | Qte de filhos que o colaborador tem |
| 4 | Fumante | Flag se o colaborador é fumante ou não fumante |
| 5 | Região | Região do Brasil onde o colaborador mora |
| 6 | Custo_Saude | Custo de Plano de Saúde que esse colaborador trouxe para a empresa no último ano |
2.2 Análise Exploratória de Dados (AED)#
Nesta primeira fase do projeto, aplicaremos técnicas de Estatística Descritiva para resumir e organizar os dados coletados por meio de tabelas, gráficos ou medidas numéricas, em busca de regularidades ou padrões nas observações que geram insights.
2.2.1 Pré-análise dos Dados#
O objetivo desta etapa é identificar dados perdidos, valores que foram armazenados incorretamente na base de dados, valores discrepantes e inconsistências que possam afetar seriamente as conclusões obtidas a partir dos dados, colocando em risco a qualidade das decisões decorrentes.
Dados perdidos (missing data)
base.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1338 entries, 0 to 1337
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Idade 1338 non-null int64
1 Sexo 1338 non-null object
2 IMC 1338 non-null float64
3 Qte_Filhos 1338 non-null int64
4 Fumante 1338 non-null object
5 Região 1338 non-null object
6 Custo_Saude 1338 non-null float64
dtypes: float64(2), int64(2), object(3)
memory usage: 73.3+ KB
Aparentemente, nenhum valor missing na base e os tipos das variáveis condizentes com os metadados.
Verificando valores duplicados:
base.duplicated().sum()
1
base.loc[base.duplicated(keep=False) == True]
| Idade | Sexo | IMC | Qte_Filhos | Fumante | Região | Custo_Saude | |
|---|---|---|---|---|---|---|---|
| 195 | 19 | Masculino | 30.59 | 0 | Não | Norte | 163.95631 |
| 581 | 19 | Masculino | 30.59 | 0 | Não | Norte | 163.95631 |
base.loc[base['Custo_Saude'] == 163.95631]
| Idade | Sexo | IMC | Qte_Filhos | Fumante | Região | Custo_Saude | |
|---|---|---|---|---|---|---|---|
| 195 | 19 | Masculino | 30.59 | 0 | Não | Norte | 163.95631 |
| 581 | 19 | Masculino | 30.59 | 0 | Não | Norte | 163.95631 |
Embora as linhas acima pareçam estar duplicadas e o valor do custo de saúde não seja tão comum nesta amostra, não há informação suficiente para identificar se pertencem ao mesmo indivíduo ou é apenas uma coincidência, desta forma optou-se por mantê-los na base.
2.2.2 Distribuição de Frequências#
A construção da distribuição de frequências exige que os possíveis valores da variável sejam discriminados e seja contado o número de vezes em que cada valor ocorreu no conjunto de dados.
2.2.2.1 Distribuição de Frequências para variáveis quantitativas (numéricas)#
# Separando as variáveis quantitativas (numéricas) das demais variáveis
numerical_variables = base.select_dtypes(include=['int64', 'float64'])
Medidas de Posição e Dispersão
numerical_variables.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Idade | 1338.0 | 39.207025 | 14.049960 | 18.00000 | 27.000000 | 39.0000 | 51.000000 | 64.000000 |
| IMC | 1338.0 | 30.663397 | 6.098187 | 15.96000 | 26.296250 | 30.4000 | 34.693750 | 53.130000 |
| Qte_Filhos | 1338.0 | 1.094918 | 1.205493 | 0.00000 | 0.000000 | 1.0000 | 2.000000 | 5.000000 |
| Custo_Saude | 1338.0 | 1327.042227 | 1211.001124 | 112.18739 | 474.028715 | 938.2033 | 1663.991252 | 6377.042801 |
Boxplots e histogramas
Show code cell source
# Boxplots e histogramas
def plot_boxplot_and_histogram(dataframe):
# Configuração do tamanho do gráfico
plt.figure(figsize=(15, 5))
# Criar uma paleta de cores com uma cor diferente para cada variável
colors = sns.color_palette("tab10", len(dataframe.columns))
# Iterar sobre cada feature e criar boxplot e histograma
for i, var in enumerate(dataframe.columns, 1):
# Subplot para boxplot
plt.subplot(2, dataframe.shape[1], i)
sns.boxplot(data=dataframe[var], showmeans=True,
meanprops={"marker": "+",
"markeredgecolor": "black",
"markersize": "10"}, color=colors[i-1])
# Subplot para histograma
plt.subplot(2, dataframe.shape[1], i + dataframe.shape[1])
sns.histplot(data=dataframe, x=var, alpha=0.7, color=colors[i-1], edgecolor='black')
# Configuração do título
plt.suptitle('Boxplot e Histograma de variáveis numéricas')
plt.tight_layout()
plt.subplots_adjust(
top=0.9, right=0.9, # Ajustar a posição do título
wspace=0.4, hspace=0.3) # Ajustar os espaçamentos entre os plots
plt.show()
# plotando a função com 'numerical_variables'
plot_boxplot_and_histogram(numerical_variables)
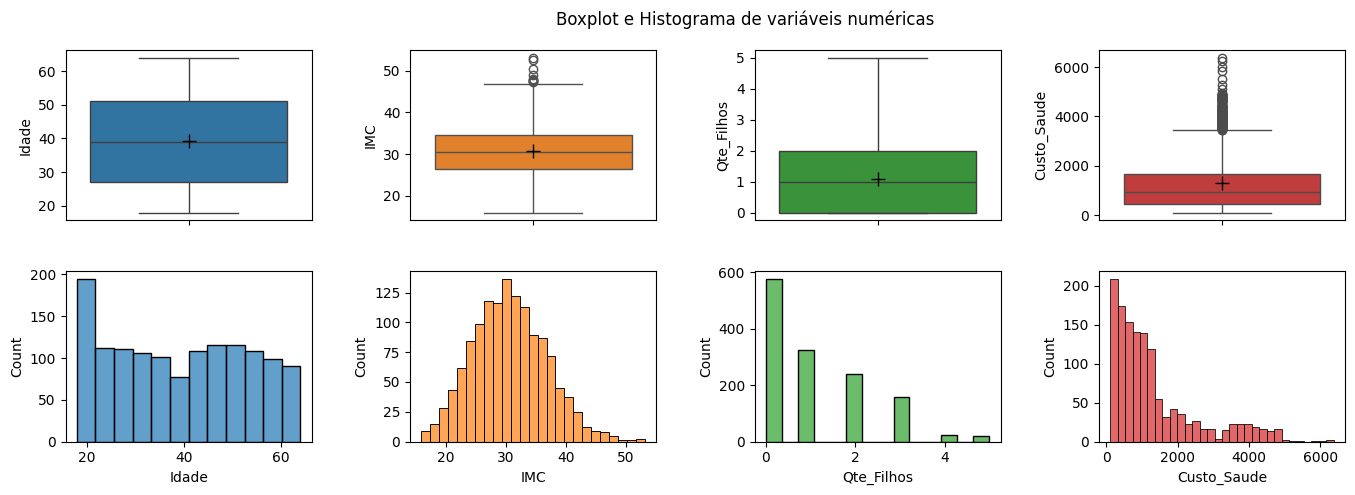
Insights
As estatísticas descritivas fornecem uma compreensão inicial do conjunto de dados, servindo como base para análises mais aprofundadas sobre os padrões e tendências presentes. Observando o resumo estatístico das variáveis quantitativas acima, é possível notar que:
Idade:
Não parece haver nada de incomum entre as idades de 18 anos a 64 anos, pois elas estão dentro de faixas razoáveis para uma população adulta, sendo que 50% dos colaboradores tem entre 27 e 51 anos, conforme indicado pelo intervalo interquartil.
A idade média e mediana dos colaboradores são de aproximadamente 39 anos, com um desvio padrão de cerca de 14 anos, indicando uma dispersão considerável em torno da média.
IMC (Índice de Massa Corporal):
O IMC mínimo de 15.96 (Muito abaixo do peso) e o máximo de 53.13 (Obesidade Mórbida) são bastante extremos e incomuns, mas não são impossíveis. De qualquer forma, valores extremos podem ser considerados discrepantes e devem ser investigados.
A média e a mediana do IMC são de aproximadamente 30, indicando que, em contrapartida, 50% dos colaboradores estão na faixa de obesidade.
Para uma melhor interpretação do IMC, podemos investigar as distribuições por categorias.
Quantidade de Filhos:
A quantidade de filhos varia de 0 a 5, sendo 50% com até 1 filho e 75% com até 2 filhos.
A média de filhos é de aproximadamente 1 por colaborador, com um desvio padrão de cerca de 1,21, indicando uma variabilidade significativa na quantidade de filhos.
Custo do Plano de Saúde:
O custo do plano de saúde varia de
R$ 112,19aR$ 6.377,04sendo 75% atéR$ 1.663.99, indicando uma concentração de altos custos nos últimos 25%. Isso sugere que pode haver alguns custos médicos excepcionalmente altos para certos indivíduos, podendo ser resultado de condições médicas graves, tratamentos caros ou até mesmo erros nos dados. Novamente, valores tão extremos podem ser considerados discrepantes e devem ser investigados.O custo médio do plano de saúde é de aproximadamente
R$ 1.327.04com um desvio padrão de cerca deR$ 1.211.00indicando uma grande dispersão nos custos entre os colaboradores.Boa parte dos custos (50%) está entre
R$ 474,02eR$ 1.663,99, conforme indicado pelo intervalo interquartil.
2.2.2.2 Distribuição de Frequências para variáveis qualitativas (categóricas)#
Para uma melhor interpretação do IMC, criaremos categorias condizentes com as medidas internacionais de Índice de massa corporal:
Resultado |
Situação |
|---|---|
Abaixo de 17 |
Muito abaixo do peso |
Entre 17 e 18,49 |
Abaixo do peso |
Entre 18,50 e 24,99 |
Peso normal |
Entre 25 e 29,99 |
Acima do peso |
Entre 30 e 34,99 |
Obesidade I |
Entre 35 e 39,99 |
Obesidade II (severa) |
Acima de 40 |
Obesidade III (mórbida) |
Show code cell source
resultado = [float('-inf'), 16.99, 18.49, 24.99, 29.99, 34.99, 39.99, float('inf')]
situacao = ["Muito abaixo do peso", "Abaixo do peso", "Peso normal", "Acima do peso", "Obesidade I", "Obesidade II", "Obesidade III"]
base['Categorias_IMC'] = pd.cut(
base['IMC'],
bins=resultado,
labels=situacao
)
base.head(5)
| Idade | Sexo | IMC | Qte_Filhos | Fumante | Região | Custo_Saude | Categorias_IMC | |
|---|---|---|---|---|---|---|---|---|
| 0 | 19 | Feminino | 27.900 | 0 | Sim | Centro | 1688.492400 | Acima do peso |
| 1 | 18 | Masculino | 33.770 | 1 | Não | Sudeste | 172.555230 | Obesidade I |
| 2 | 28 | Masculino | 33.000 | 3 | Não | Sudeste | 444.946200 | Obesidade I |
| 3 | 33 | Masculino | 22.705 | 0 | Não | Norte | 2198.447061 | Peso normal |
| 4 | 32 | Masculino | 28.880 | 0 | Não | Norte | 386.685520 | Acima do peso |
# Separando as variáveis qualitativas (categóricas) das demais variáveis
categorical_variables = base.select_dtypes(include=['object', 'category'])
Show code cell source
# Definindo a função de tabelas de frequência
def tabela_frequencia_qualitativa(df, variavel_qualitativa, metadados: dict = None, ordem = None, bins = None):
"""
Gera tabelas de frequência absoluta, relativa e acumulada para uma variável qualitativa em um DataFrame.
Parâmetros:
- df: DataFrame pandas contendo os dados.
- variavel_qualitativa: Nome da coluna que representa a variável qualitativa.
- metadados: Dicionário opcional de metadados para mapear os valores da variável qualitativa.
- ordem: Lista opcional que especifica a ordem desejada para o índice da tabela de frequência.
Se None (padrão), assume-se que a variável é nominal e não existe ordenação dentre as categorias.
Se uma lista é fornecida, a variável é tratada como ordinal e existe uma ordenação entre as categorias.
- bins: Tamanho de faixas de agrupamento para variaveis quantitativas.
Retorna:
- DataFrame contendo tabelas de frequência com as colunas 'Frequência Absoluta', 'Frequência Relativa' e 'Frequência Acumulada'.
"""
# Verifica se df é um DataFrame
if not isinstance(df, pd.DataFrame):
raise ValueError(f"O argumento 'df' deve ser um DataFrame do pandas, mas foi fornecido um objeto do tipo {type(df)}.")
# Verifica se a variável qualitativa está presente no DataFrame
if variavel_qualitativa not in df.columns:
raise ValueError(f"A coluna '{variavel_qualitativa}' não está presente no DataFrame.")
dataframe_variavel_qualitativa = df[variavel_qualitativa]
if metadados:
dataframe_variavel_qualitativa = dataframe_variavel_qualitativa.map(metadados)
if bins:
sort=False
else:
sort=True
# Calcula a frequência absoluta
frequencia_absoluta = dataframe_variavel_qualitativa.value_counts(bins = bins, sort=sort)
if isinstance(df[variavel_qualitativa].dtype, pd.CategoricalDtype):
ordem = (list(df[variavel_qualitativa].dtype.categories.values))
# Reindexa a frequencia_absoluta antes de calcular as outras frequências se uma ordem específica foi fornecida para o índice
if ordem:
# Verifica se os valores de ordem estão presente no index
if not all(valor in ordem for valor in dataframe_variavel_qualitativa.unique()):
raise ValueError(f"Pelo menos um valor de '{ordem}' está diferente ou não está em '{list(dataframe_variavel_qualitativa.unique())}'.")
frequencia_absoluta = frequencia_absoluta.reindex(ordem)
# Calcula as frequências relativa e acumulada
frequencia_relativa = frequencia_absoluta / len(dataframe_variavel_qualitativa)
frequencia_acumulada = frequencia_relativa.cumsum()
# Formata as colunas 'Frequência Relativa' e 'Frequência Acumulada'
formato_percentual = lambda x: f'{x:.2%}'
tabela_frequencia = pd.DataFrame({
'Frequência Absoluta': frequencia_absoluta,
'Frequência Relativa': frequencia_relativa.map(formato_percentual),
'Frequência Acumulada': frequencia_acumulada.map(formato_percentual)
}).rename_axis(variavel_qualitativa)
return tabela_frequencia
# Tabelas de frequência
for var in categorical_variables.columns:
print("\nTabela frequência de", var)
display(tabela_frequencia_qualitativa(categorical_variables, var))
Tabela frequência de Sexo
| Frequência Absoluta | Frequência Relativa | Frequência Acumulada | |
|---|---|---|---|
| Sexo | |||
| Masculino | 676 | 50.52% | 50.52% |
| Feminino | 662 | 49.48% | 100.00% |
Tabela frequência de Fumante
| Frequência Absoluta | Frequência Relativa | Frequência Acumulada | |
|---|---|---|---|
| Fumante | |||
| Não | 1064 | 79.52% | 79.52% |
| Sim | 274 | 20.48% | 100.00% |
Tabela frequência de Região
| Frequência Absoluta | Frequência Relativa | Frequência Acumulada | |
|---|---|---|---|
| Região | |||
| Sudeste | 364 | 27.20% | 27.20% |
| Centro | 325 | 24.29% | 51.49% |
| Norte | 325 | 24.29% | 75.78% |
| Nordeste | 324 | 24.22% | 100.00% |
Tabela frequência de Categorias_IMC
| Frequência Absoluta | Frequência Relativa | Frequência Acumulada | |
|---|---|---|---|
| Categorias_IMC | |||
| Muito abaixo do peso | 3 | 0.22% | 0.22% |
| Abaixo do peso | 17 | 1.27% | 1.49% |
| Peso normal | 225 | 16.82% | 18.31% |
| Acima do peso | 386 | 28.85% | 47.16% |
| Obesidade I | 391 | 29.22% | 76.38% |
| Obesidade II | 224 | 16.74% | 93.12% |
| Obesidade III | 92 | 6.88% | 100.00% |
Insights
Podemos obter os seguintes insights nas tabelas de frequência das variáveis qualitativas:
Sexo: A proporção de homens (50,52%) e mulheres (49,48%) na amostra são muito próximas, indicando uma distribuição equitativa entre os sexos.
Fumante: A frequência de fumantes na empresa é de 20,48%, o que representa uma diferença significativa em relação à taxa nacional de fumantes com 18 anos ou mais, que é de 9,3% (dados do Vigitel 2023). Essa diferença de 11,18 pontos percentuais destaca a importância de estratégias específicas para redução do tabagismo entre os colaboradores e pode ser adotada como meta inicial de redução da taxa na empresa.
Região: A distribuição dos colaboradores por região apresenta frequências muito similares.
Categorias de IMC (Índice de Massa Corporal): A maioria dos indivíduos na amostra se encontram na categoria Obesidade I (29,22%), no entanto, somadas as obesidades I, II e III nota-se que mais da metade dos colaboradores estão obesos. Isso destaca a necessidade de implementar programas de gerenciamento de peso e promoção de hábitos saudáveis, como alimentação equilibrada e prática regular de exercícios físicos, visando reduzir os custos associados a condições relacionadas à obesidade.
Observando as distribuições das variáveis Sexo e Região, podemos confirmar a utilização da amostragem estratificada, na qual a divisão em grupos (estratos), buscam representar as subpopulações presentes na população. Esse método evita possíveis distorções na análise, proporcionando uma representação mais precisa e equilibrada dos dados coletados.
3. Preparação dos Dados#
3.1 Seleção das variáveis#
3.1.1 Análise de Correlação e Associação#
Nesta etapa, analisaremos o comportamento conjunto de duas variáveis investigando potenciais relações causais para o custo do plano de saúde da empresa. Isso nos possibilitará abordar as questões de negócios levantadas, tais como:
Quais fatores estão mais relacionados com o custo do plano de saúde?
Que tipo de ações preventivas a empresa pode fazer de forma a diminuir esse custo?
3.1.1.1 Análise de Correlação e medidas de associação entre variáveis numéricas#
Show code cell source
# Gráficos de dispersão com linha de regressão
# Colunas que queremos plotar em relação a 'Custo_Saude'
columns_to_plot = ['Idade', 'IMC', 'Qte_Filhos']
# Criando a figura e os subplots
fig, axes = plt.subplots(1, len(columns_to_plot), sharey=True, figsize=(15, 5))
# Iterando sobre as colunas e criando os gráficos de dispersão com linha de regressão
for i, col in enumerate(columns_to_plot):
sns.regplot(x=col, y='Custo_Saude', data=base, ax=axes[i], line_kws=dict(color="r"))
# Calculando o coeficiente de correlação (r)
r = base[col].corr(base['Custo_Saude'])
axes[i].set_title(f'{col} vs. Custo de Saúde (r={r:.2f})')
axes[i].set_xlabel(col)
axes[i].set_ylabel('Custo de Saúde')
# Exibindo o gráfico
plt.tight_layout()
plt.show()
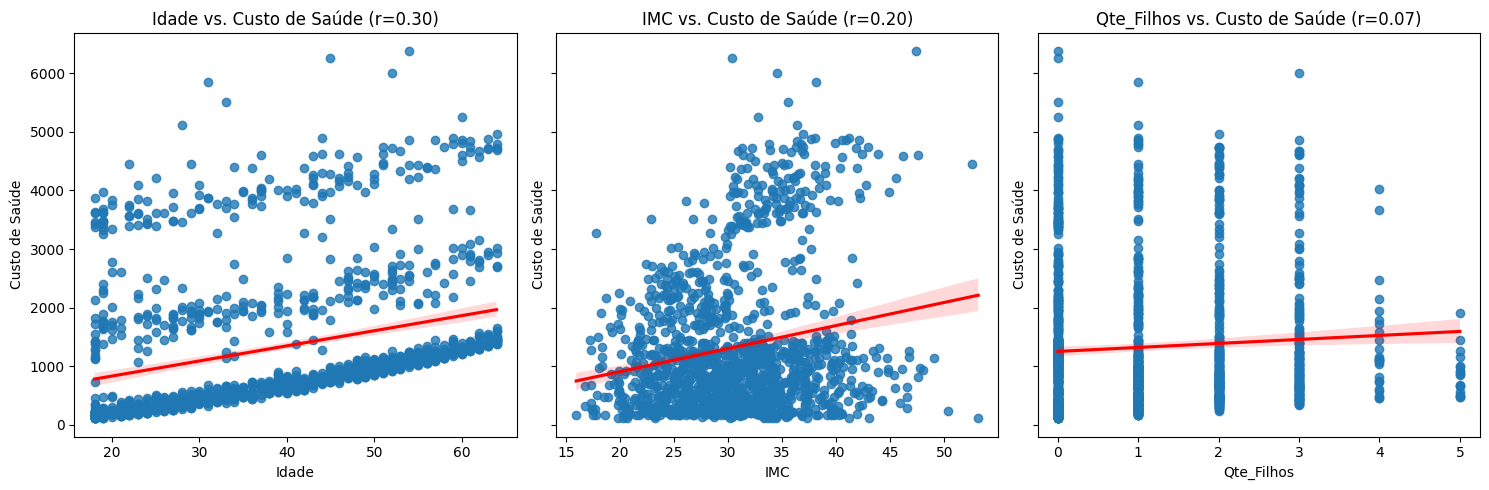
Insights
Observando o gráfico de dispersão notamos a existência de uma relação fraca entre as variáveis explicativas quantitativas e a variável alvo “Custo_Saude”:
Embora haja uma relação ligeiramente positiva na dispersão entre idade e o custo de saúde, a presença de agrupamentos lineares sugere que a variabilidade pode estar associada a outros fatores, os quais podem ou não estar presentes em nosso conjunto de dados.
O mesmo padrão é observado na variável IMC, que apresenta dois agrupamentos distintos.
A dispersão entre a quantidade de filhos e o custo de saúde apresenta um comportamento incomum. Mesmo que a relação entre as duas variáveis seja ligeiramente positiva, a maior variância está em quantidades menores de filhos.
Coeficiente de Correlação de Pearson entre variáveis numéricas
Show code cell source
# Calculando a matriz de correlação
correlation_matrix = numerical_variables.corr()
# Plotando a matriz de correlação usando seaborn
sns.set_theme(style='white')
mask = np.triu(np.ones_like(correlation_matrix, dtype=bool))
cmap = sns.diverging_palette(230, 20, as_cmap=True)
plt.figure(figsize=(15, 5))
sns.heatmap(correlation_matrix, mask=mask, vmin=-1, vmax=1, cmap=cmap, annot=True, fmt=".2f", annot_kws={"size": 10}, linewidths=.5)
plt.title('Matriz de Correlação')
plt.show()
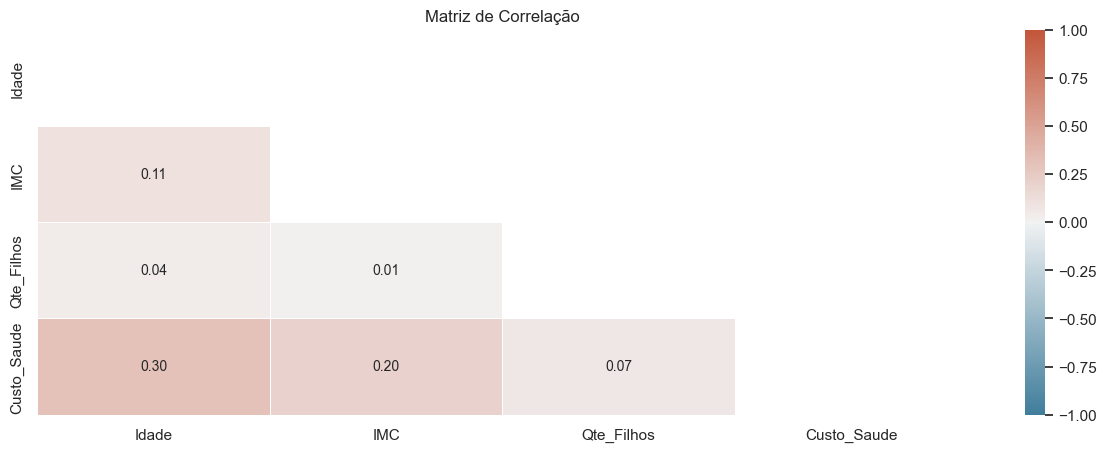
Pouca correlação entre as variáveis numéricas.
3.1.1.2 Análise de Correlação e medidas de associação entre variáveis categóricas#
Podemos analisar a distribuição da variável Custo_Saude, que é uma variável quantitativa, em relação a cada variável categórica construindo boxplots individuais para cada categoria.
Show code cell source
# Boxplots de variáveis categóricas x Custo_Saude
# Configurar o tamanho do gráfico
plt.figure(figsize=(15, 8))
# Iterar sobre cada feature e criar boxplot
for i, var in enumerate(categorical_variables.columns, 1):
plt.subplot(2, 2, i)
sns.boxplot(x=var, y='Custo_Saude', data=base, hue=var, showmeans=True,
meanprops={"marker": "+",
"markeredgecolor": "black",
"markersize": "10"})
plt.xticks(rotation=45, ha="right")
plt.subplots_adjust(hspace=0.5)
plt.subplots_adjust(wspace=0.3)
# Configurar título
plt.suptitle('Boxplots de variáveis categóricas em relação a Custo_Saude')
plt.subplots_adjust(top=0.9, right=0.9) # Ajustar a posição da legenda
#plt.tight_layout()
plt.show()
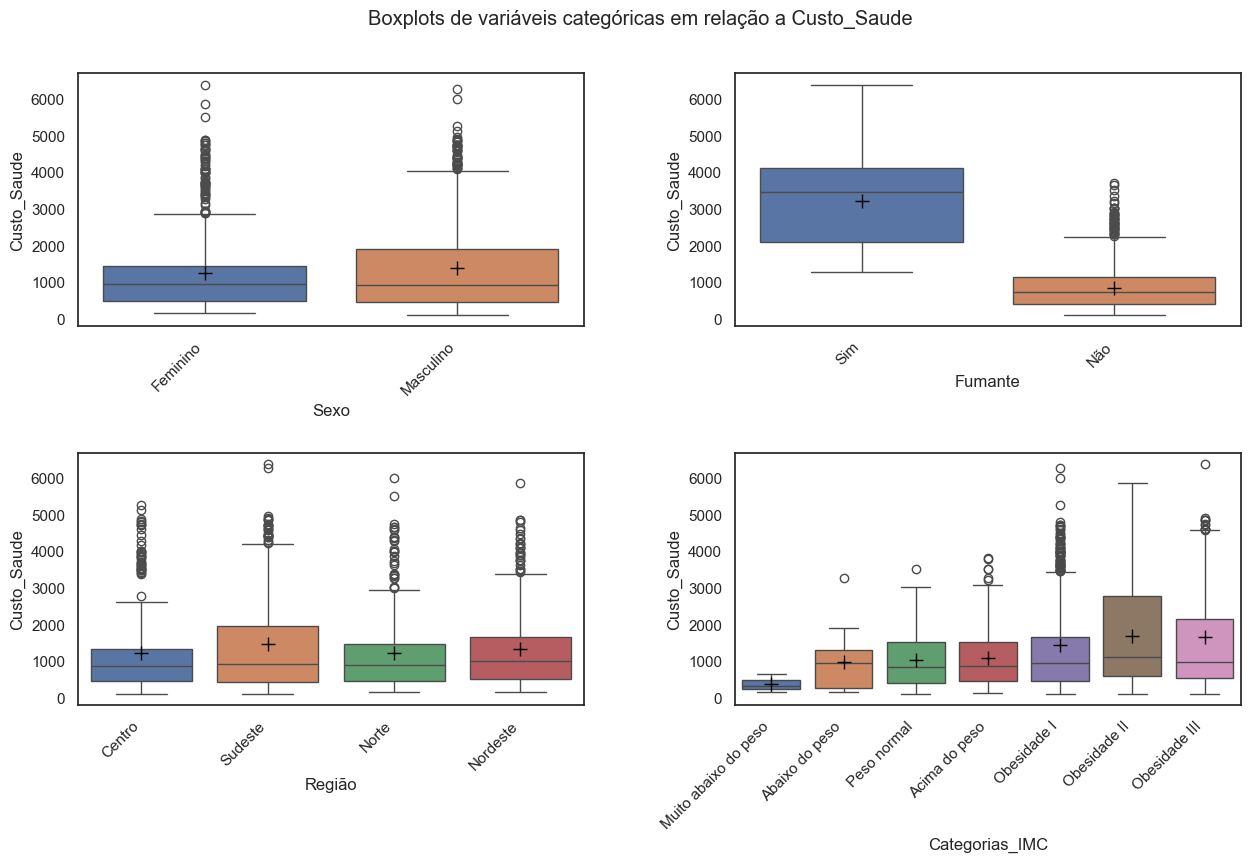
Insights
As distribuições dos custos de saúde entre homens e mulheres são semelhantes até o segundo quartil. A partir desse ponto, as distribuições para o sexo masculino apresentam uma maior dispersão nos quartis subsequentes e muitas observações discrepantes (outliers) para os dois sexos.
As medidas de posição do custo de saúde pela variável fumante indicam uma disparidade significativa na distribuição entre fumantes e não fumantes. É altamente provável que essa variável tenha uma forte influência na explicação da variabilidade do “Custo_Saude” pelo modelo de regressão linear, resultando em um aumento do R². Isso implica que as estimativas geradas pelo modelo serão ainda mais precisas na prática.
As regiões apresentam um número significativo de observações discrepantes (outliers) nos custos de saúde, sendo a região Sudeste a que possui a maior dispersão para os custos.
As categorias de IMC apresentam médias e dispersões superiores para as três classes de obesidade em comparação com as demais classes.
Para medir a associação entre variáveis qualitativas e a variável Custo_Saude utilizamos o Coeficiente de Determinação (R²)
Show code cell source
# Função r2
def r2(df, feature, target):
"""
Calcula o Coeficiente de Determinação (R²) para uma variável qualitativa e uma variável quantitativa em um DataFrame.
Parâmetros:
- df: DataFrame pandas contendo os dados.
- feature: Nome da coluna que representa a variável qualitativa.
- Para calculo de R² combinado, informar uma lista de variáveis.
- target: Nome da coluna que representa a variável quantitativa.
Retorna:
- Coeficiente de Determinação (R²) em (%) e nomes da feature e target em uma tupla.
"""
varp = lambda x: np.var(x, ddof=0)
# Criar tabela de contagem e variância
tabela = pd.pivot_table(df, values=target, index=feature, aggfunc=['count', varp], margins=True, margins_name='Total') #margins=True retorna os totais
tabela.columns = ['N', 'varp']
# Separando o total dos demais dados
total = tabela.loc[[tabela.last_valid_index()]]
# Filtrando os demais dados sem o total e removendo linhas NaN.
tabela = tabela.drop(tabela.last_valid_index()).dropna()
# Calcular variância ponderada total
var_ponderada = (tabela['N'] @ tabela['varp']) / total['N'].values[0]
# Calcular R²
r2_valor = 1 - (var_ponderada / total['varp'].values[0])
r2_valor = round(r2_valor * 100, 2)
return feature, target, r2_valor
# Iterando entre as variáveis categóricas para calcular o r2
for var in categorical_variables.columns:
print(r2(base, var, 'Custo_Saude'))
('Sexo', 'Custo_Saude', 0.33)
('Fumante', 'Custo_Saude', 61.98)
('Região', 'Custo_Saude', 0.66)
('Categorias_IMC', 'Custo_Saude', 4.66)
A variável Fumante explica 61,98% dos custos de saúde na empresa, seguida por Categorias_IMC que explica apenas 4,66% desses custos.
3.1.2 Análise Multivariada#
3.1.2.1 Distribuição das variáveis categóricas no Custo_Saude x Idade#
Show code cell source
# Configurar o tamanho do gráfico
plt.figure(figsize=(15, 8))
# Iterar sobre cada feature e criar boxplot
for i, var in enumerate(categorical_variables.columns, 1):
plt.subplot(2, 2, i)
sns.scatterplot(x='Idade', y='Custo_Saude', data=base, hue=var)
plt.subplots_adjust(hspace=0.5)
plt.subplots_adjust(wspace=0.3)
# Configurar título
plt.suptitle('Distribuição das variáveis categóricas no Custo_Saude x Idade')
plt.subplots_adjust(top=0.9, right=0.9) # Ajustar a posição da legenda
#plt.tight_layout()
plt.show()
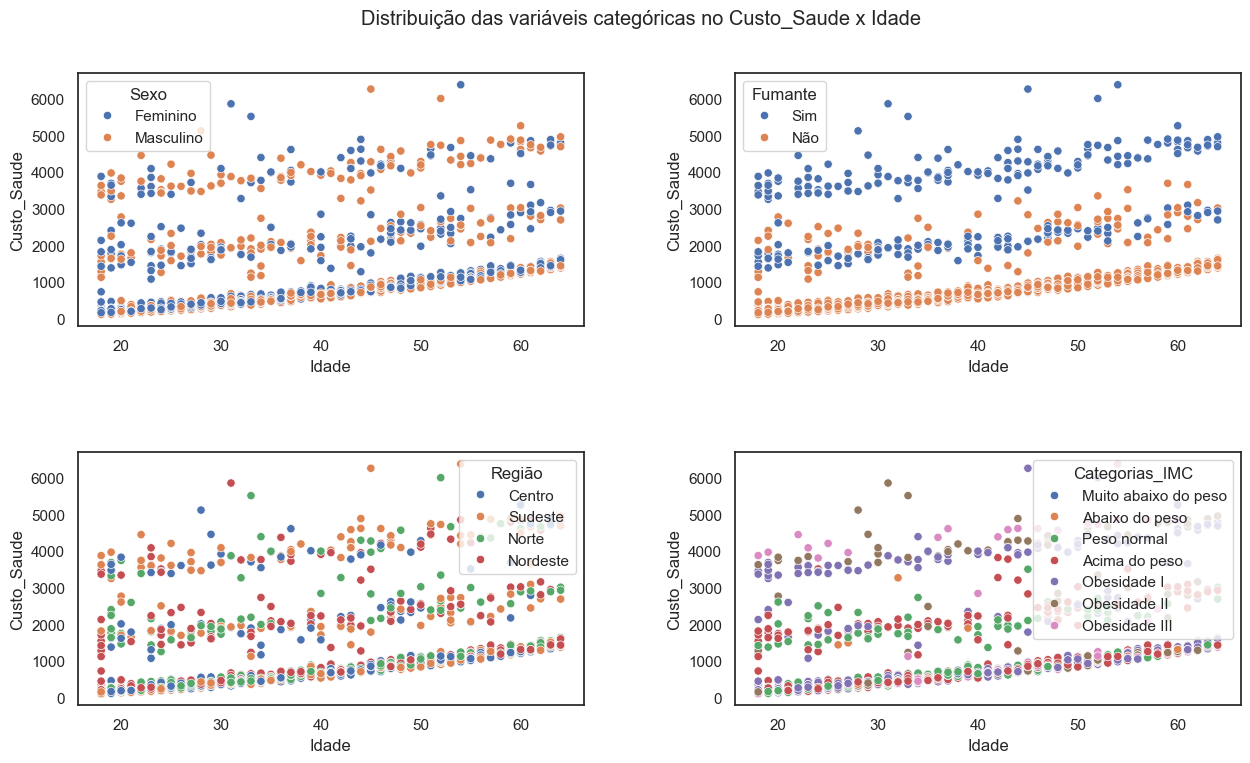
Nos gráficos apresentados, é possível observar a distribuição das classes de variáveis categóricas em relação ao custo de saúde versus idade, destacando um agrupamento de colaboradores fumantes com custos máximos e não fumantes com custos mínimos no plano de saúde.
3.1.2.2 Distribuição das variáveis categóricas no Custo_Saude x IMC#
Show code cell source
# Configurar o tamanho do gráfico
plt.figure(figsize=(15, 8))
# Iterar sobre cada feature e criar boxplot
for i, var in enumerate(categorical_variables.columns, 1):
plt.subplot(2, 2, i)
sns.scatterplot(x='IMC', y='Custo_Saude', data=base, hue=var)
plt.subplots_adjust(hspace=0.5)
plt.subplots_adjust(wspace=0.3)
# Configurar título
plt.suptitle('Distribuição das variáveis categóricas no Custo_Saude x IMC')
plt.subplots_adjust(top=0.9, right=0.9) # Ajustar a posição da legenda
#plt.tight_layout()
plt.show()
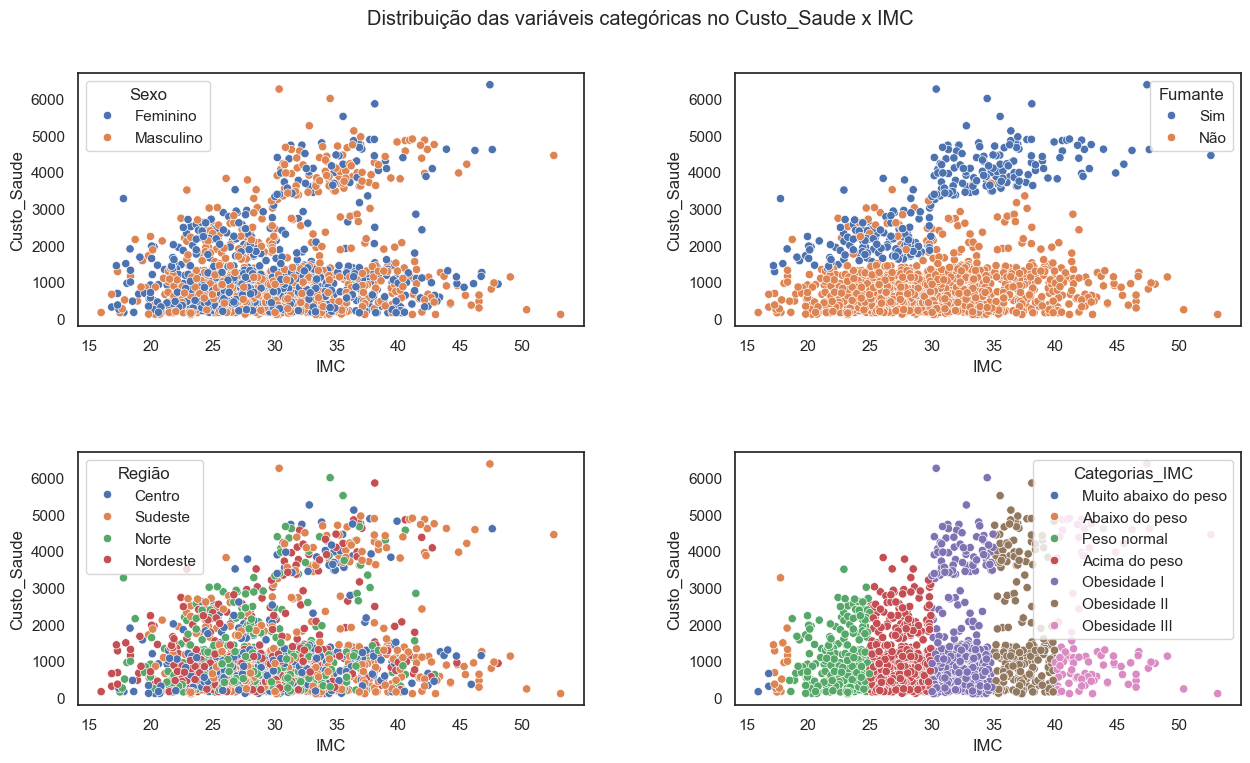
A variável “Fumante” exerce uma influência considerável nos custos de saúde, especialmente quando combinada com um Índice de Massa Corporal (IMC) superior a 30, ou seja, fumantes com obesidade.
3.1.2.3 Distribuição das variáveis categóricas no Custo_Saude x Qte_Filhos#
Show code cell source
# Configurar o tamanho do gráfico
plt.figure(figsize=(15, 8))
# Iterar sobre cada feature e criar boxplot
for i, var in enumerate(categorical_variables.columns, 1):
plt.subplot(2, 2, i)
sns.scatterplot(x='Qte_Filhos', y='Custo_Saude', data=base, hue=var)
plt.subplots_adjust(hspace=0.5)
plt.subplots_adjust(wspace=0.3)
# Configurar título
plt.suptitle('Distribuição das variáveis categóricas no Custo_Saude x Qte_Filhos')
plt.subplots_adjust(top=0.9, right=0.9) # Ajustar a posição da legenda
#plt.tight_layout()
plt.show()
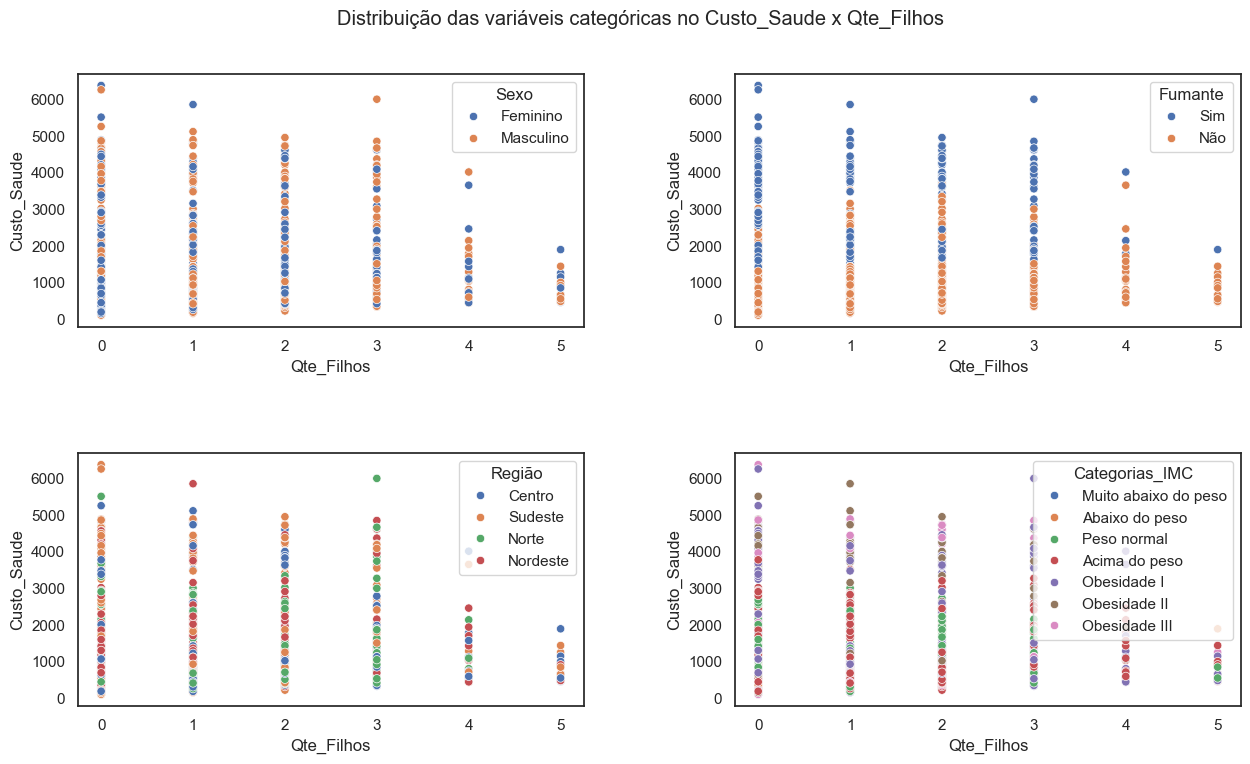
Aparentemente, ter mais filhos não resulta em um aumento significativo nos custos do plano de saúde, ao contrário do que inicialmente se pensava. Mais uma vez, é a variável “Fumante” quem está associada ao aumento nos custos.
3.1.2.4 Boxplots de categorias de Fumantes por Região em relação a Custo_Saude#
Show code cell source
g = sns.catplot(
data=base,
x='Região', y='Custo_Saude', hue='Região', palette='Set2',
kind="box", orient="v",
showmeans=True,
meanprops={
"marker": "+",
"markeredgecolor": "black",
"markersize": "10"},
sharex=False, margin_titles=True,
height=5, aspect=1.3,
col="Fumante"
)
# Configurar título
g.figure.suptitle('Boxplots de categorias de Fumantes por Região em relação a Custo_Saude')
g.figure.subplots_adjust(top=0.75, right=0.9) # Ajustar a posição da legenda
g.set_titles(col_template="Fumante: {col_name}")
plt.show()
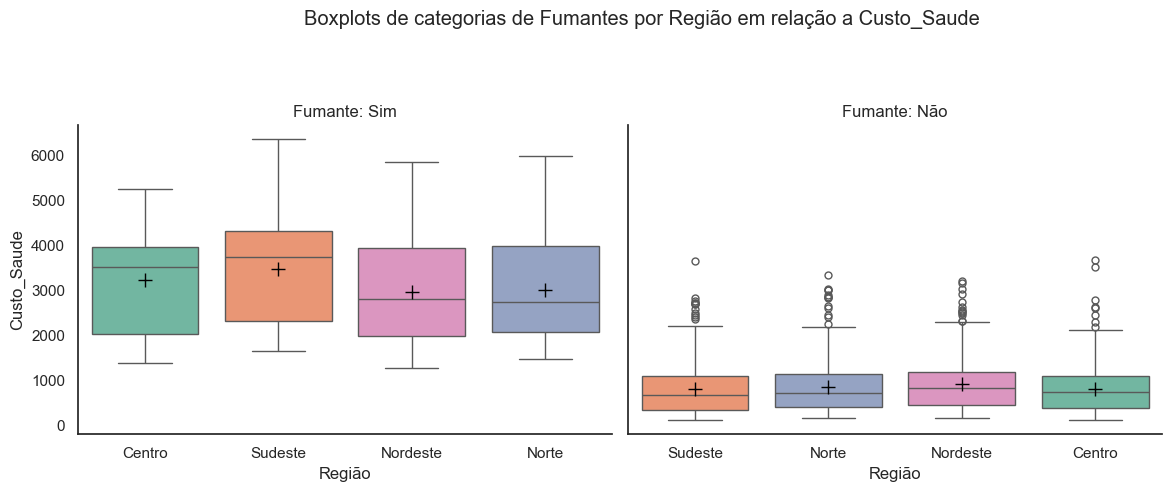
A análise dos boxplots sugere que a variável região não exerce um impacto significativo nos custos de saúde entre fumantes e não fumantes, indicando que não há contribuições relevantes desta variável para o aumento dos custos de saúde.
3.1.2.5 Boxplots de categorias de Fumantes por Sexo em relação a Custo_Saude#
Show code cell source
g = sns.catplot(
data=base,
x='Sexo', y='Custo_Saude', hue='Sexo', palette='Set2',
kind="box", orient="v",
showmeans=True,
meanprops={
"marker": "+",
"markeredgecolor": "black",
"markersize": "10"},
sharex=False, margin_titles=True,
height=5, aspect=1.3,
col="Fumante"
)
# Configurar título
g.figure.suptitle('Boxplots de categorias de Fumantes por Sexo em relação a Custo_Saude')
g.figure.subplots_adjust(top=0.75, right=0.9) # Ajustar a posição da legenda
g.set_titles(col_template="Fumante: {col_name}")
plt.show()
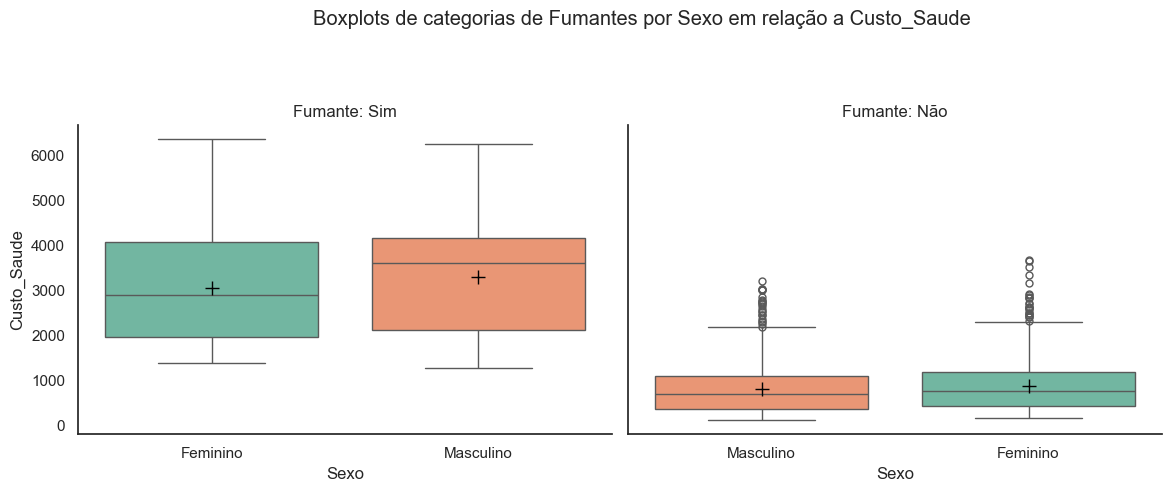
Da mesma forma, a variável sexo aparenta não contribuir para o aumento dos custos de saúde entre fumantes.
3.1.2.6 Boxplots de categorias de Fumantes por Categorias_IMC em relação a Custo_Saude#
Show code cell source
g = sns.catplot(
data=base,
x='Categorias_IMC', y='Custo_Saude', hue='Categorias_IMC', palette='Set2',
kind="box", orient="v",
showmeans=True,
meanprops={
"marker": "+",
"markeredgecolor": "black",
"markersize": "10"},
sharex=False, margin_titles=True,
height=6, aspect=1.3,
col="Fumante"
)
# Configurar título
g.figure.suptitle('Boxplots de categorias de Fumantes por Categorias_IMC em relação a Custo_Saude')
g.figure.subplots_adjust(top=0.75, right=0.9) # Ajustar a posição da legenda
g.set_xticklabels(rotation=20)
g.set_titles(col_template="Fumante: {col_name}")
plt.show()
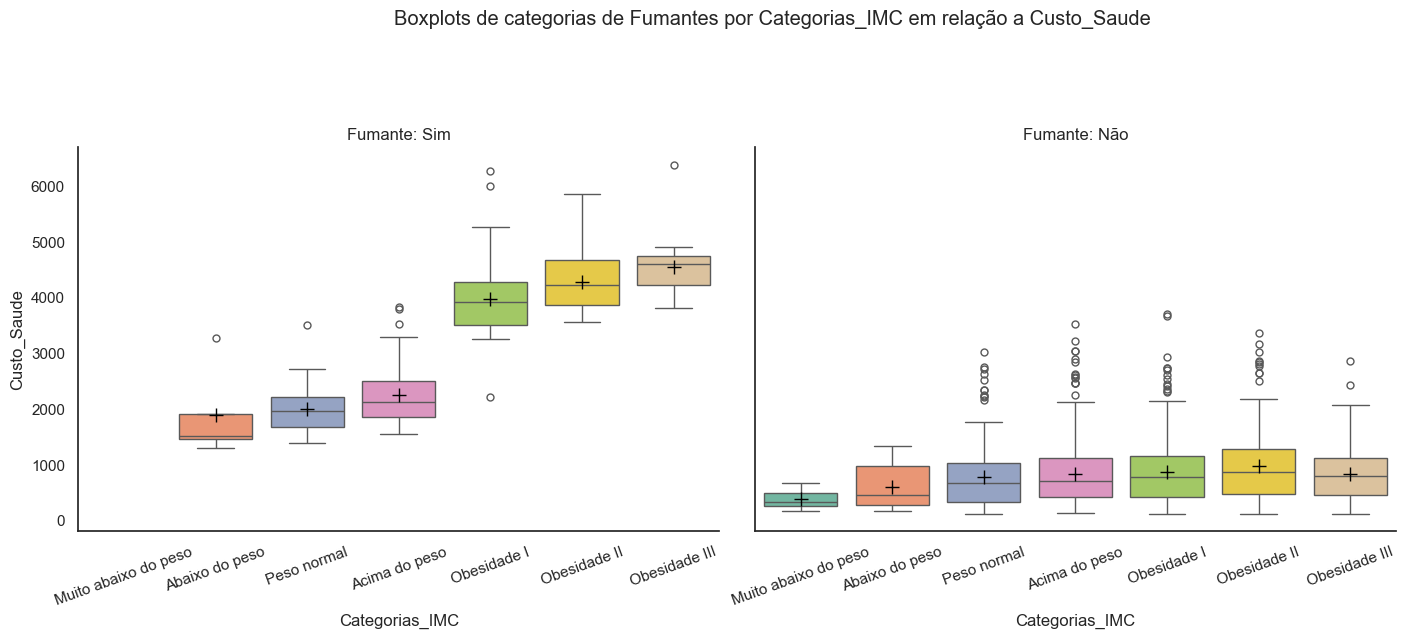
Por outro lado, as categorias de IMC revelam um aumento progressivo nos custos para as combinações de fumantes com obesidade I, II e III, sugerindo uma contribuição significativa para o nosso modelo de regressão.
3.1.2.7 Medindo o R² de combinações pareadas de variáveis categóricas#
Show code cell source
import itertools
# Gerando todas as combinações possíveis de tamanho 2 entre as variáveis
combinations = list(itertools.combinations(categorical_variables.columns, 2))
for var in combinations:
print(r2(base, var, 'Custo_Saude'))
(('Sexo', 'Fumante'), 'Custo_Saude', 62.23)
(('Sexo', 'Região'), 'Custo_Saude', 1.15)
(('Sexo', 'Categorias_IMC'), 'Custo_Saude', 5.24)
(('Fumante', 'Região'), 'Custo_Saude', 62.75)
(('Fumante', 'Categorias_IMC'), 'Custo_Saude', 76.9)
(('Região', 'Categorias_IMC'), 'Custo_Saude', 5.74)
Finalmente, mensuramos que as variáveis Fumante e Categorias_IMC, em conjunto, explicam 76,9% dos custos de saúde na empresa, o que representa um incremento de 14,92 pontos percentuais em relação à variável Fumante isolada, que explicava apenas 61,98%.
4. Desenvolvendo o Modelo Inferencial#
Nas etapas anteriores, identificamos as variáveis que influenciam os altos custos de saúde na empresa. No entanto, podemos refinar ainda mais nosso entendimento, ajustando um modelo de regressão linear com todas as variáveis e realizando um processo iterativo para determinar quais variáveis devem ser incluídas ou excluídas do modelo. Desta forma, nesta etapa do projeto, aplicaremos a técnica “Regressão Linear Múltipla” para entender como cada variável explica o custo de saúde.
4.1 Amostragem estratificada#
Neste estudo, observa-se que a amostragem é estratificada, dividida em grupos populacionais (estratos) com base em características específicas. Neste método de coleta de dados, uma amostra é selecionada de cada estrato, assegurando representatividade de toda a população e inclusão de todas as subpopulações na amostra.
Confirmando que a amostra aleatória foi coletada de forma estratificada pelas variáveis sexo e região:
Show code cell source
print('Porcentagem por sexo na amostra:')
print(base['Sexo'].value_counts(normalize=True)*100)
print('\nPorcentagem por região na amostra:')
print(base['Região'].value_counts(normalize=True)*100)
Porcentagem por sexo na amostra:
Sexo
Masculino 50.523169
Feminino 49.476831
Name: proportion, dtype: float64
Porcentagem por região na amostra:
Região
Sudeste 27.204783
Centro 24.289985
Norte 24.289985
Nordeste 24.215247
Name: proportion, dtype: float64
4.2 Tamanho da amostra#
O cálculo do tamanho da amostra é importante, pois quanto maior a amostra, mais precisa será a estimativa da população. Vamos assumir um erro amostral de 5% e considerar que a população total é composta por aproximadamente 20 mil colaboradores.
4.2.1 Cálculo amostral utilizando a fórmula de Slovin#
Show code cell source
# Função para cálculo amostral padrão para uma população heterogênea
def calculoAmostral(e, N):
n = (N / (1 + (N*(e**2))))
return (n)
# Erro amostral definido para o estudo
erro = 0.05
# População estimada para o estudo
populacao = 20000
# Cálculo da amostra
amostra = calculoAmostral(erro, populacao)
# arredondar o resultado para valores inteiros
tamanho = round(amostra)
print(f'A partir da fórmula de Slovin, foi estimado {tamanho} como um tamanho amostral mínimo.')
A partir da fórmula de Slovin, foi estimado 392 como um tamanho amostral mínimo.
4.3 Preparação dos Dados#
# Removendo a variável 'Categorias_IMC' para evitar multicolinearidade com IMC
df = base.drop('Categorias_IMC', axis=1)
# Criando variáveis Dummy
df = pd.get_dummies(df, dtype=int, drop_first=True)
df.sample(5, random_state=42)
| Idade | IMC | Qte_Filhos | Custo_Saude | Sexo_Masculino | Fumante_Sim | Região_Nordeste | Região_Norte | Região_Sudeste | |
|---|---|---|---|---|---|---|---|---|---|
| 764 | 45 | 25.175 | 2 | 909.506825 | 0 | 0 | 1 | 0 | 0 |
| 887 | 36 | 30.020 | 0 | 527.217580 | 0 | 0 | 0 | 1 | 0 |
| 890 | 64 | 26.885 | 0 | 2933.098315 | 0 | 1 | 0 | 1 | 0 |
| 1293 | 46 | 25.745 | 3 | 930.189355 | 1 | 0 | 0 | 1 | 0 |
| 259 | 19 | 31.920 | 0 | 3375.029180 | 1 | 1 | 0 | 1 | 0 |
df.columns
Index(['Idade', 'IMC', 'Qte_Filhos', 'Custo_Saude', 'Sexo_Masculino',
'Fumante_Sim', 'Região_Nordeste', 'Região_Norte', 'Região_Sudeste'],
dtype='object')
#Separando as variáveis
# Variável resposta
y = df['Custo_Saude']
# Variáveis explicativas
x = df.drop('Custo_Saude', axis=1)
# Definindo o intercepto na posição 0 do dataframe
x.insert(0, 'intercepto', 1)
4.4 Ajuste do Modelo de Regressão Linear Múltipla#
Para ajustar o modelo, adotaremos o método de seleção de variáveis baseado no p-valor, utilizando a exclusão progressiva. Iniciaremos com um modelo contendo todas as variáveis e, em seguida, removeremos uma a uma, mantendo apenas aquelas com p-valores significativamente baixos. Essa abordagem é uma técnica amplamente utilizada na seleção de variáveis em modelos de regressão linear, visando alcançar um modelo mais conciso e elucidativo.
# Ajusta o modelo e retorna os resultados
modelo = sm.OLS(y , x)
resultado = modelo.fit()
print(resultado.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Custo_Saude R-squared: 0.751
Model: OLS Adj. R-squared: 0.749
Method: Least Squares F-statistic: 500.8
Date: sex, 06 set 2024 Prob (F-statistic): 0.00
Time: 13:58:19 Log-Likelihood: -10467.
No. Observations: 1338 AIC: 2.095e+04
Df Residuals: 1329 BIC: 2.100e+04
Df Model: 8
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
intercepto -1289.8590 102.096 -12.634 0.000 -1490.147 -1089.571
Idade 25.6856 1.190 21.587 0.000 23.351 28.020
IMC 33.9193 2.860 11.860 0.000 28.309 39.530
Qte_Filhos 47.5501 13.780 3.451 0.001 20.516 74.584
Sexo_Masculino -13.1314 33.295 -0.394 0.693 -78.447 52.184
Fumante_Sim 2384.8535 41.315 57.723 0.000 2303.803 2465.904
Região_Nordeste 96.0051 47.793 2.009 0.045 2.247 189.764
Região_Norte 60.7087 47.720 1.272 0.204 -32.907 154.324
Região_Sudeste -7.4971 47.064 -0.159 0.873 -99.825 84.830
==============================================================================
Omnibus: 300.366 Durbin-Watson: 2.088
Prob(Omnibus): 0.000 Jarque-Bera (JB): 718.887
Skew: 1.211 Prob(JB): 7.86e-157
Kurtosis: 5.651 Cond. No. 326.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Como o coeficiente da variável ‘Região_Sudeste’ e de outras variáveis apresentou-se estatisticamente igual a zero, vamos excluí-las do modelo. No entanto, para avaliar o verdadeiro impacto no modelo, é recomendado remover uma variável de cada vez e observar as mudanças resultantes.
#removendo a variável Região_Sudeste que apresentou o maior p-valor
x = x.drop('Região_Sudeste', axis=1)
# Ajusta o modelo e retorna os resultados
modelo = sm.OLS(y , x)
resultado = modelo.fit()
print(resultado.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Custo_Saude R-squared: 0.751
Model: OLS Adj. R-squared: 0.750
Method: Least Squares F-statistic: 572.8
Date: sex, 06 set 2024 Prob (F-statistic): 0.00
Time: 13:58:19 Log-Likelihood: -10467.
No. Observations: 1338 AIC: 2.095e+04
Df Residuals: 1330 BIC: 2.099e+04
Df Model: 7
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
intercepto -1291.5392 101.513 -12.723 0.000 -1490.682 -1092.396
Idade 25.6913 1.189 21.609 0.000 23.359 28.024
IMC 33.8419 2.817 12.012 0.000 28.315 39.369
Qte_Filhos 47.6147 13.769 3.458 0.001 20.603 74.627
Sexo_Masculino -13.1318 33.282 -0.395 0.693 -78.423 52.160
Fumante_Sim 2384.4299 41.215 57.854 0.000 2303.577 2465.283
Região_Nordeste 99.7414 41.627 2.396 0.017 18.080 181.403
Região_Norte 64.4289 41.600 1.549 0.122 -17.180 146.038
==============================================================================
Omnibus: 300.090 Durbin-Watson: 2.088
Prob(Omnibus): 0.000 Jarque-Bera (JB): 717.871
Skew: 1.210 Prob(JB): 1.31e-156
Kurtosis: 5.649 Cond. No. 320.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
#removendo a variável Sexo_Masculino que apresentou o maior p-valor
x = x.drop('Sexo_Masculino', axis=1)
# Ajusta o modelo e retorna os resultados
modelo = sm.OLS(y , x)
resultado = modelo.fit()
print(resultado.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Custo_Saude R-squared: 0.751
Model: OLS Adj. R-squared: 0.750
Method: Least Squares F-statistic: 668.6
Date: sex, 06 set 2024 Prob (F-statistic): 0.00
Time: 13:58:19 Log-Likelihood: -10467.
No. Observations: 1338 AIC: 2.095e+04
Df Residuals: 1331 BIC: 2.098e+04
Df Model: 6
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
intercepto -1296.6452 100.653 -12.882 0.000 -1494.100 -1099.190
Idade 25.7030 1.188 21.632 0.000 23.372 28.034
IMC 33.7890 2.813 12.011 0.000 28.270 39.308
Qte_Filhos 47.5213 13.763 3.453 0.001 20.522 74.521
Fumante_Sim 2383.2064 41.085 58.007 0.000 2302.609 2463.804
Região_Nordeste 99.6744 41.613 2.395 0.017 18.039 181.309
Região_Norte 64.4401 41.587 1.550 0.121 -17.143 146.023
==============================================================================
Omnibus: 300.460 Durbin-Watson: 2.089
Prob(Omnibus): 0.000 Jarque-Bera (JB): 719.502
Skew: 1.211 Prob(JB): 5.78e-157
Kurtosis: 5.653 Cond. No. 318.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
#removendo a variável Região_Norte que apresentou o maior p-valor
x = x.drop('Região_Norte', axis=1)
# Ajusta o modelo e retorna os resultados
modelo = sm.OLS(y , x)
resultado = modelo.fit()
print(resultado.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Custo_Saude R-squared: 0.750
Model: OLS Adj. R-squared: 0.749
Method: Least Squares F-statistic: 801.0
Date: sex, 06 set 2024 Prob (F-statistic): 0.00
Time: 13:58:19 Log-Likelihood: -10468.
No. Observations: 1338 AIC: 2.095e+04
Df Residuals: 1332 BIC: 2.098e+04
Df Model: 5
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
intercepto -1251.2095 96.337 -12.988 0.000 -1440.199 -1062.220
Idade 25.7406 1.189 21.657 0.000 23.409 28.072
IMC 32.9463 2.762 11.930 0.000 27.529 38.364
Qte_Filhos 47.9514 13.767 3.483 0.001 20.943 74.960
Fumante_Sim 2380.8135 41.077 57.959 0.000 2300.230 2461.397
Região_Nordeste 77.3946 39.071 1.981 0.048 0.747 154.042
==============================================================================
Omnibus: 302.023 Durbin-Watson: 2.083
Prob(Omnibus): 0.000 Jarque-Bera (JB): 727.655
Skew: 1.215 Prob(JB): 9.81e-159
Kurtosis: 5.674 Cond. No. 300.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
#removendo a variável Região_Nordeste que apresentou o maior p-valor
x = x.drop('Região_Nordeste', axis=1)
# Ajusta o modelo e retorna os resultados
modelo = sm.OLS(y , x)
resultado = modelo.fit()
print(resultado.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Custo_Saude R-squared: 0.750
Model: OLS Adj. R-squared: 0.749
Method: Least Squares F-statistic: 998.1
Date: sex, 06 set 2024 Prob (F-statistic): 0.00
Time: 13:58:19 Log-Likelihood: -10470.
No. Observations: 1338 AIC: 2.095e+04
Df Residuals: 1333 BIC: 2.098e+04
Df Model: 4
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
intercepto -1210.2769 94.198 -12.848 0.000 -1395.070 -1025.484
Idade 25.7850 1.190 21.675 0.000 23.451 28.119
IMC 32.1851 2.738 11.756 0.000 26.814 37.556
Qte_Filhos 47.3502 13.779 3.436 0.001 20.319 74.381
Fumante_Sim 2381.1400 41.122 57.904 0.000 2300.469 2461.811
==============================================================================
Omnibus: 301.480 Durbin-Watson: 2.087
Prob(Omnibus): 0.000 Jarque-Bera (JB): 722.157
Skew: 1.215 Prob(JB): 1.53e-157
Kurtosis: 5.654 Cond. No. 292.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
5. Validação do trabalho#
5.1 Diagnóstico do Modelo: Análise dos Resíduos#
Para que o modelo de Regressão Linear Múltipla possa dar boas estimativas com o mínimo de viés possível, algumas premissas/suposições devem ser atendidas.
5.1.1 Ausência de multicolinearidade#
Show code cell source
g = sns.pairplot(base[['Idade', 'IMC', 'Qte_Filhos']])
# Configurar título
# Definir o tamanho da figura
g.figure.set_size_inches(15, 10)
g.figure.suptitle('Dispersão entre as variáveis do modelo', fontsize=16)
g.figure.subplots_adjust(top=0.90, right=0.9) # Ajustar a posição da legenda
plt.show()
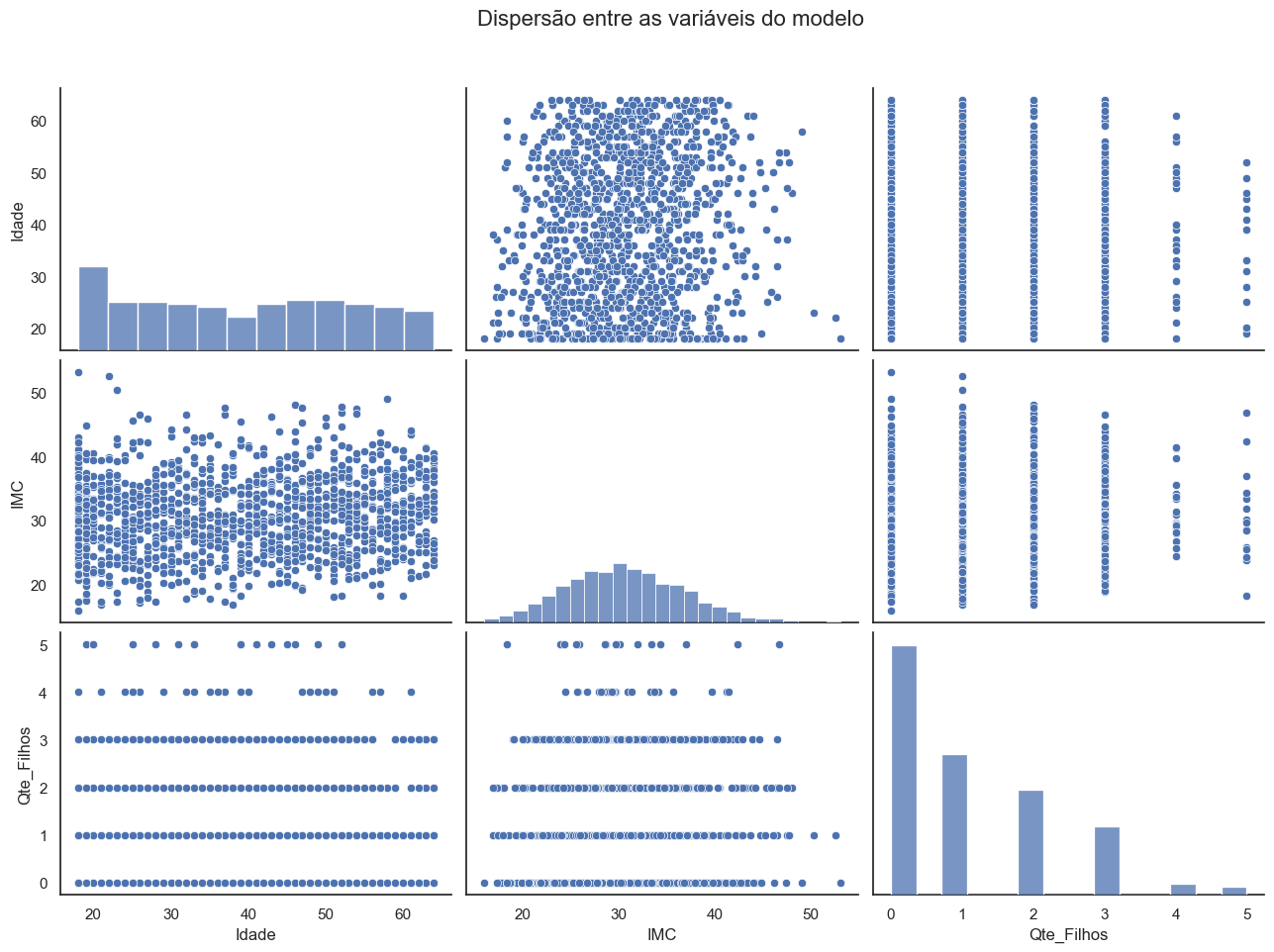
A distribuição das variáveis no gráfico de dispersão sugere que elas se comportam de forma independente, descartando a presença de multicolinearidade no modelo.
5.1.2 Normalidade dos Resíduos#
O erro deve ter média próxima de zero:
round(resultado.resid.mean(), 2)
0.0
Show code cell source
# Função para gerar gráfico dos residuos
def grafico_residuos(resultado):
plt.figure(figsize=(15, 5))
resid_graf = sns.scatterplot(x=list(range(0,len(resultado.resid_pearson))),
y=resultado.resid_pearson.tolist())
# Localizando valor mínimo dos resíduos
r_aux = resultado.resid_pearson.tolist()
r_aux.append(-3)
ymin = min(r_aux) * 1.1
# Localizando valor máximo dos resíduos
r_aux = resultado.resid_pearson.tolist()
r_aux.append(+3)
ymax = max(r_aux) * 1.1
resid_graf.set(ylim=(ymin, ymax))
ax1 = resid_graf.axes
ax1.axhline( 0, color='black', ls='--')
ax1.axhline(-2, color='black', ls='--')
ax1.axhline(+2, color='black', ls='--')
plt.title('Dispersão dos resíduos')
plt.show()
grafico_residuos(resultado)
Show code cell source
# Construção de histograma para avaliar a distribuição dos resíduos
plt.figure(figsize=(15, 5))
sns.histplot(resultado.resid_pearson, kde=True)
plt.title('Distribuição dos resíduos')
plt.show()
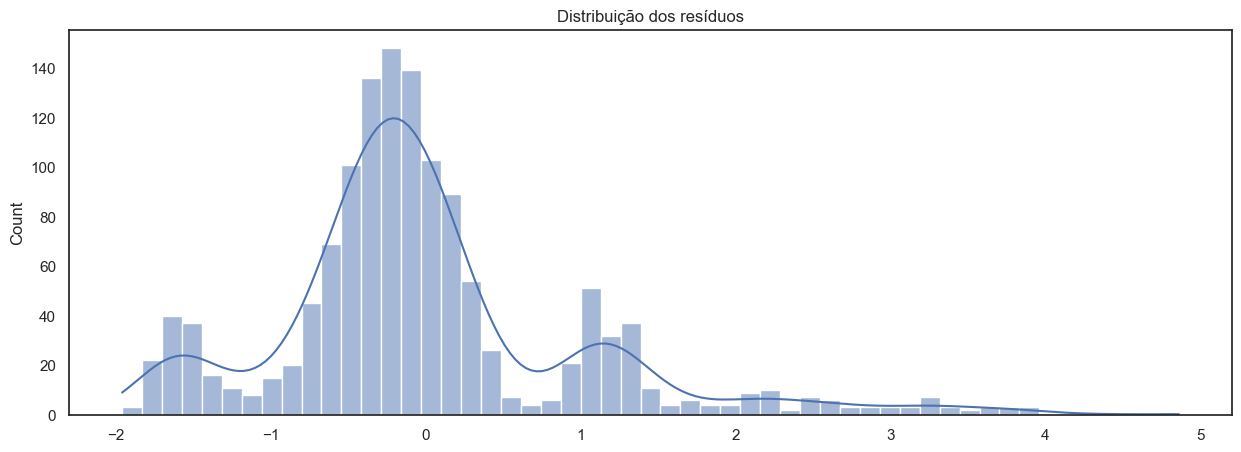
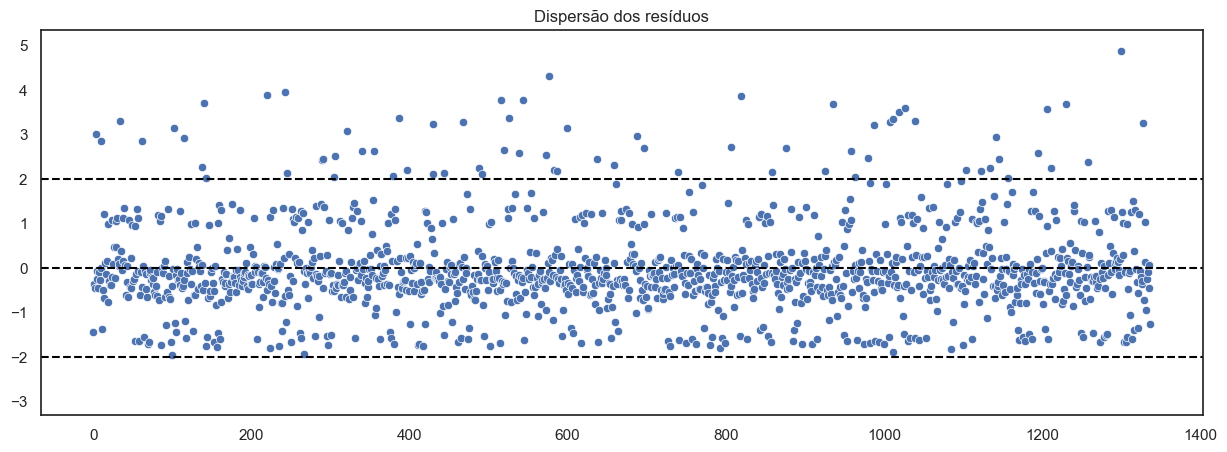
A análise da dispersão e do histograma dos resíduos revela a presença de dois picos menores além da concentração central em torno de zero. Essa distribuição sugere que o modelo atual não está capturando completamente a variabilidade dos dados. A introdução de uma nova variável relevante pode ser necessária para explicar essa variabilidade adicional e aprimorar o ajuste do modelo.
Teste de Hipóteses para avaliar Normalidade:
Show code cell source
# Realização de Teste de Hipóteses para avaliar Normalidade
from scipy.stats import shapiro
normalidade = shapiro(resultado.resid_pearson)
print('Estatística=%.3f, p-valor=%.3f\n' % (normalidade.statistic, normalidade.pvalue))
Estatística=0.900, p-valor=0.000
O resultado p-valor < 0.05 no teste de Shapiro-Wilk indica que deve-se rejeitar a hipótese nula, ou seja, os resíduos da regressão linear múltipla não seguem uma distribuição normal. No entanto, a estatística de teste é 0.900 (quanto mais próximo de 1, mais normalmente distribuídos são os resíduos), o que sugere que os resíduos estão relativamente próximos de uma distribuição normal, mas não perfeitamente.
5.1.3 Homocedasticidade dos Resíduos#
Show code cell source
from statsmodels.stats.diagnostic import het_white
labels = ['LM Statistic', 'LM-Test p-value', 'F-Statistic', 'F-Test p-value']
white_test = het_white(resultado.resid_pearson,
resultado.model.exog)
print(dict(zip(labels, white_test)))
{'LM Statistic': 128.47065644118692, 'LM-Test p-value': 4.214011485296054e-21, 'F-Statistic': 10.81763109783478, 'F-Test p-value': 3.040778066492286e-22}
Com base nos resultados, podemos concluir que há evidência estatística para rejeitar a hipótese nula de homocedasticidade. Isso indica que os resíduos da regressão linear múltipla exibem heterocedasticidade, o que sugere que a variância dos erros não é constante.
5.1.4 Premissas/Suposições para o Modelo Inferencial#
Checklist do modelo de regressão linear:
As variáveis explicativas devem ser lineares com a variável resposta.
A amostra deve ser aleatória.
Ausência de multicolinearidade perfeita (as variáveis independentes devem ter pouca correlação/associação entre si).
O erro (diferença entre a variável resposta e a estimativa do modelo) deve ter média próxima de zero.
O erro deve ter uma distribuição próxima da distribuição Normal.
A dispersão de cada variável explicativa com erro deve ser constante, ao redor de 0 (zero). Essa suposição é chamada de Homocedasticidade.
Quando uma ou mais suposições não são atendidas, o processo de estimativa pode ter viés e, portanto, não há garantias de que as conclusões sejam boas o suficiente para se tomar uma decisão.
5.2 Interpretação do Modelo#
Equação do Modelo:
Custo_Saude = \(\beta_0\) + \(\beta_1\) x Idade + \(\beta_2\) x IMC + \(\beta_3\) x Qte_Filhos + \(\beta_4\) x Fumante_Sim
\(\beta_0\) ou Intercepto:
-R$1.210,28.\(\beta_1\) x Idade: Para cada ano de idade, mantendo todas as outras variáveis constantes, o custo de saúde aumenta em média
R$25,79.\(\beta_2\) x IMC: Cada unidade do IMC, mantendo todas as outras variáveis constantes, têm um aumento médio no custo de saúde de
R$32,19.\(\beta_3\) x Qte_Filhos: Cada filho adicional, mantendo todas as outras variáveis constantes, gera um aumento médio de
R$47,35.\(\beta_4\) x Fumante_Sim: Funcionários que são fumantes, mantendo todas as outras variáveis constantes, têm um custo médio de
R$2.381,14a mais que os não fumantes.
5.3 Verificação dos critérios de sucesso#
5.3.1 Estimativas populacionais de ganho geral#
Simulação de ganho com a Cessação do Tabagismo na empresa:
Calculando o intervalo de confiança para a proporção de fumantes na amostra:
Show code cell source
n_amostra = len(base['Fumante']) # tamanho da amostra
n_fumantes = len(base[base['Fumante'] == 'Sim']) # número de fumantes
# Proporção observada de fumantes na amostra
proporcao_fumantes = np.mean(base['Fumante'] == 'Sim')
# Nível de confiança desejado
confianca = 0.95
# Calcular o intervalo de confiança
limite_inferior, limite_superior = sm.stats.proportion_confint(n_fumantes, n_amostra, 1-confianca)
# Apresentar os resultados
print(f"IC de {confianca:.0%} para proporção {proporcao_fumantes:.2%} de fumantes:")
print(f"Limite inferior: {limite_inferior:.2%}")
print(f"Limite superior: {limite_superior:.2%}")
IC de 95% para proporção 20.48% de fumantes:
Limite inferior: 18.32%
Limite superior: 22.64%
Calculando a redução percentual necessária para alinhar a proporção de fumantes na empresa com a taxa nacional de fumantes:
Show code cell source
taxa_nacional_fumantes = 0.093 #dado do [Vigitel 2023] https://www.gov.br/saude/pt-br/centrais-de-conteudo/publicacoes/svsa/vigitel/vigitel-brasil-2006-2023-tabagismo-e-consumo-abusivo-de-alcool/view
reducao_fumantes = proporcao_fumantes - taxa_nacional_fumantes
qtd_a_reduzir = reducao_fumantes * n_amostra
reducao_fumantes_perc = 1 - qtd_a_reduzir/n_fumantes
print(f"Redução percentual do total de fumantes: {reducao_fumantes_perc:.2%}")
Redução percentual do total de fumantes: 45.41%
Utilizando a técnica de reamostragem bootstrap, estimamos a média do custo de saúde e calculamos um intervalo de confiança de 95%, possibilitando uma inferência robusta sobre o valor médio desse custo, mesmo diante da não normalidade da distribuição dos dados de saúde.
Show code cell source
# Realizando o bootstrap para estimar a média
res = stats.bootstrap((base['Custo_Saude'].values,), np.mean, n_resamples=1000, confidence_level=0.95, random_state=42)
custo_saude_medio = res.bootstrap_distribution.mean()
print(f"Estimativa da média de Custo_Saude: {moeda(custo_saude_medio)}")
print(f"Intervalo de confiança (95%): ( {moeda(res.confidence_interval.low)}, {moeda(res.confidence_interval.high)} )")
Estimativa da média de Custo_Saude: R$ 1.327,83
Intervalo de confiança (95%): ( R$ 1.265,29, R$ 1.391,86 )
Agora, vamos reduzir a quantidade de fumantes em 45,41% para alinhar a proporção de fumantes com a taxa nacional.
Show code cell source
# Simulação da situação em que uma % dos fumantes deixam de fumar
def simular_media_reducao_fumantes(df, reducao_fumantes):
# Criando uma cópia do DataFrame para simulação
df_simulado = df.copy()
# Selecionando aleatoriamente a % dos fumantes para deixar de fumar
num_fumantes = df_simulado[df_simulado['Fumante'] == 'Sim'].shape[0]
qtd_a_alterar = int(num_fumantes * reducao_fumantes)
indexes_a_alterar = np.random.choice(df_simulado[df_simulado['Fumante'] == 'Sim'].index, qtd_a_alterar, replace=True)
df_simulado.loc[indexes_a_alterar, 'Custo_Saude'] -= 2381.14
df_simulado['Custo_Saude'] = df_simulado['Custo_Saude'].clip(lower=0)
# Calculando o custo médio por funcionário após a mudança
custo_medio_simulado = df_simulado['Custo_Saude'].mean()
return custo_medio_simulado
# Realizando o bootstrap para estimar a economia média por funcionário
n_bootstraps = 1000
reducao_fumantes = reducao_fumantes_perc
media_reducao_fumantes = [
simular_media_reducao_fumantes(base, reducao_fumantes)
for _ in range(n_bootstraps)
]
# Calculando o intervalo de confiança para a economia média por funcionário
lower_ci = np.percentile(media_reducao_fumantes, 2.5)
upper_ci = np.percentile(media_reducao_fumantes, 97.5)
custo_saude_medio_reducao_fumantes = np.mean(media_reducao_fumantes)
print(f"Estimativa da média do custo de saúde após a redução de {reducao_fumantes:.2%} de fumantes: {moeda(custo_saude_medio_reducao_fumantes)}")
print(f"Intervalo de confiança (95%): ( {moeda(lower_ci)}, {moeda(upper_ci)} )")
Estimativa da média do custo de saúde após a redução de 45.41% de fumantes: R$ 1.162,13
Intervalo de confiança (95%): ( R$ 1.149,76, R$ 1.175,28 )
Show code cell source
custo_saude_geral = custo_saude_medio * 20000
custo_saude_geral_reducao_fumantes = custo_saude_medio_reducao_fumantes * 20000
economia_geral = custo_saude_geral - custo_saude_geral_reducao_fumantes
print(f"Redução de {(economia_geral / custo_saude_geral):.2%} no custo de saúde onde {reducao_fumantes:.0%} do total de fumantes abandonaram o fumo: {moeda(economia_geral)}")
Redução de 12.48% no custo de saúde onde 45% do total de fumantes abandonaram o fumo: R$ 3.314.110,25
Simulação de ganho com a redução de peso na empresa:
Redução média do IMC
Show code cell source
# Realizando o bootstrap para estimar a média
res = stats.bootstrap((base['IMC'].values,), np.mean, n_resamples=1000, confidence_level=0.95, random_state=42)
imc_medio = res.bootstrap_distribution.mean()
print(f"Estimativa da média de IMC: {imc_medio:.2f}")
print(f"Intervalo de confiança (95%): ({res.confidence_interval.low:.2f}, {res.confidence_interval.high:.2f})")
Estimativa da média de IMC: 30.67
Intervalo de confiança (95%): (30.33, 31.02)
Show code cell source
# Simulação da situação em que uma % dos funcionarios diminuem o IMC
def simular_media_reducao_imc(df, perc_reduc_obesidade, reducao_imc, custo_unidade_imc):
# Criando uma cópia do DataFrame para simulação
df_simulado = df.copy()
# Selecionando aleatoriamente a % dos funcionarios acima do peso para diminuir o IMC
num_acima_peso = df_simulado[df_simulado['IMC'] >= 25].shape[0]
qtd_a_alterar = int(num_acima_peso * perc_reduc_obesidade)
indexes_a_alterar = np.random.choice(df_simulado[df_simulado['IMC'] >= 25].index, qtd_a_alterar, replace=True)
df_simulado.loc[indexes_a_alterar, 'IMC'] -= reducao_imc
df_simulado.loc[indexes_a_alterar, 'Custo_Saude'] -= (custo_unidade_imc * reducao_imc)
df_simulado['Custo_Saude'] = df_simulado['Custo_Saude'].clip(lower=0)
# Calculando o custo médio por funcionário após a mudança
custo_medio_simulado = df_simulado['Custo_Saude'].mean()
# Calculando o imc médio por funcionário após a redução
imc_medio_simulado = df_simulado['IMC'].mean()
return imc_medio_simulado, custo_medio_simulado
# Realizando o bootstrap para estimar a média por funcionário com a redução do IMC
n_bootstraps = 1000
perc_reduc_obesidade = 0.50
reducao_imc = 5
custo_unidade_imc = 32.19
imc_medio_simulado = []
custo_medio_simulado = []
for _ in range(n_bootstraps):
imc, custo = simular_media_reducao_imc(base, perc_reduc_obesidade, reducao_imc, custo_unidade_imc)
imc_medio_simulado.append(imc)
custo_medio_simulado.append(custo)
# Calculando o intervalo de confiança para imc médio por funcionário
lower_ci = np.percentile(imc_medio_simulado, 2.5)
upper_ci = np.percentile(imc_medio_simulado, 97.5)
media_apos_reducao_imc = np.mean(imc_medio_simulado)
print(f"Estimativa da média do IMC após a redução do IMC em {reducao_imc:.0f} pontos para {perc_reduc_obesidade:.2%} de funcionários acima do peso: {media_apos_reducao_imc:.2f}")
print(f"Intervalo de confiança (95%): ({lower_ci:.2f}, {upper_ci:.2f})\n")
# Calculando o intervalo de confiança para custo médio por funcionário após redução de imc
lower_ci = np.percentile(custo_medio_simulado, 2.5)
upper_ci = np.percentile(custo_medio_simulado, 97.5)
custo_medio_apos_reducao_imc = np.mean(custo_medio_simulado)
print(f"Estimativa da média do custo de saúde após a redução do IMC em {reducao_imc:.0f} pontos para {perc_reduc_obesidade:.2%} de funcionários acima do peso: {moeda(custo_medio_apos_reducao_imc)}")
print(f"Intervalo de confiança (95%): ({moeda(lower_ci)}, {moeda(upper_ci)})")
Estimativa da média do IMC após a redução do IMC em 5 pontos para 50.00% de funcionários acima do peso: 29.06
Intervalo de confiança (95%): (29.00, 29.11)
Estimativa da média do custo de saúde após a redução do IMC em 5 pontos para 50.00% de funcionários acima do peso: R$ 1.275,52
Intervalo de confiança (95%): (R$ 1.273,68, R$ 1.277,39)
Show code cell source
custo_saude_geral = custo_saude_medio * 20000
custo_saude_geral_reducao_obesos = custo_medio_apos_reducao_imc * 20000
economia_geral = custo_saude_geral - custo_saude_geral_reducao_obesos
print(f"Redução de {(economia_geral / custo_saude_geral):.2%} no custo de saúde onde {perc_reduc_obesidade:.0%} do total de funcionários acima do peso reduziram o imc em {reducao_imc:.0f} pontos: {moeda(economia_geral)}")
Redução de 3.94% no custo de saúde onde 50% do total de funcionários acima do peso reduziram o imc em 5 pontos: R$ 1.046.281,25
6. Implantação#
6.1 Plano de implantação#
Plano de Ação 5W2H para Redução de Custos com Saúde na Empresa
Objetivo: Reduzir os custos com saúde dos colaboradores em 15% em 2 anos, com foco nos principais fatores de risco: tabagismo e IMC alto.
Público-alvo: Todos os colaboradores da empresa (mais de 20 mil) em todo o Brasil.
Prazo: 2 anos
Recursos:
Equipe de Recursos Humanos
Equipe de Saúde Ocupacional
Parceiros externos (nutricionistas, psicólogos, empresas de cessação do tabagismo)
Recursos financeiros para implementação das ações
Ações:
Show code cell source
# Dados da tabela
data = {
'O quê': [
'Programa de Cessação do Tabagismo',
'Programa de Redução de Peso',
'Exames Médicos Preventivos',
'Monitoramento e Avaliação',
'Comunicação e Engajamento'
],
'Quem': [
'Equipe de Saúde Ocupacional, Psicólogos, Empresas de Cessação do Tabagismo',
'Equipe de Saúde Ocupacional, Nutricionistas',
'Equipe de Saúde Ocupacional',
'Equipe de Saúde Ocupacional',
'Equipe de Comunicação, Equipe de Saúde Ocupacional'
],
'Quando': ['Contínuo', 'Contínuo', 'Anual', 'Semestral', 'Contínuo'],
'Onde': ['Locais de trabalho e online', 'Locais de trabalho e online', 'Locais de trabalho e clínicas parceiras', 'Análise de dados', 'Canais de comunicação internos da empresa'],
'Por quê': [
'Reduzir o número de fumantes entre os colaboradores e prevenir doenças relacionadas ao tabagismo',
'Reduzir o IMC dos colaboradores e prevenir doenças relacionadas ao sobrepeso e obesidade',
'Detectar precocemente doenças e promover a saúde preventiva',
'Avaliar o impacto das ações e identificar áreas para melhorias',
'Informar os colaboradores sobre as ações disponíveis e seus benefícios, incentivar a participação nos programas e atividades, campanhas de conscientização sobre os fatores de risco para a saúde e como preveni-los'
],
'Como': [
'Workshops e palestras sobre os malefícios do tabagismo, terapia individual ou em grupo, medicações, acompanhamento psicológico, ambientes livres de fumo, apoio aos fumantes',
'Workshops sobre nutrição, grupos de apoio para perda de peso, acesso a nutricionistas, opções de lanches saudáveis nos refeitórios, desafios de atividade física',
'Oferecer exames médicos periódicos gratuitos ou com baixo custo, campanhas de conscientização sobre a importância dos exames preventivos, acesso facilitado aos exames',
'Coletar dados sobre o custo com saúde dos funcionários, IMC, taxa de tabagismo e frequência de exames preventivos, análise periódica dos dados, ajustes no plano conforme necessário',
'Campanhas de comunicação interna, materiais informativos, treinamentos, eventos'
],
'Quanto': ['A definir'] * 5
}
# Criando o DataFrame
df = pd.DataFrame(data)
# Definindo 'O quê' como índice
df.set_index('O quê', inplace=True)
df
| Quem | Quando | Onde | Por quê | Como | Quanto | |
|---|---|---|---|---|---|---|
| O quê | ||||||
| Programa de Cessação do Tabagismo | Equipe de Saúde Ocupacional, Psicólogos, Empresas de Cessação do Tabagismo | Contínuo | Locais de trabalho e online | Reduzir o número de fumantes entre os colaboradores e prevenir doenças relacionadas ao tabagismo | Workshops e palestras sobre os malefícios do tabagismo, terapia individual ou em grupo, medicações, acompanhamento psicológico, ambientes livres de fumo, apoio aos fumantes | A definir |
| Programa de Redução de Peso | Equipe de Saúde Ocupacional, Nutricionistas | Contínuo | Locais de trabalho e online | Reduzir o IMC dos colaboradores e prevenir doenças relacionadas ao sobrepeso e obesidade | Workshops sobre nutrição, grupos de apoio para perda de peso, acesso a nutricionistas, opções de lanches saudáveis nos refeitórios, desafios de atividade física | A definir |
| Exames Médicos Preventivos | Equipe de Saúde Ocupacional | Anual | Locais de trabalho e clínicas parceiras | Detectar precocemente doenças e promover a saúde preventiva | Oferecer exames médicos periódicos gratuitos ou com baixo custo, campanhas de conscientização sobre a importância dos exames preventivos, acesso facilitado aos exames | A definir |
| Monitoramento e Avaliação | Equipe de Saúde Ocupacional | Semestral | Análise de dados | Avaliar o impacto das ações e identificar áreas para melhorias | Coletar dados sobre o custo com saúde dos funcionários, IMC, taxa de tabagismo e frequência de exames preventivos, análise periódica dos dados, ajustes no plano conforme necessário | A definir |
| Comunicação e Engajamento | Equipe de Comunicação, Equipe de Saúde Ocupacional | Contínuo | Canais de comunicação internos da empresa | Informar os colaboradores sobre as ações disponíveis e seus benefícios, incentivar a participação nos programas e atividades, campanhas de conscientização sobre os fatores de risco para a saúde e como preveni-los | Campanhas de comunicação interna, materiais informativos, treinamentos, eventos | A definir |
Indicadores de Sucesso:
Redução de 15% no custo com saúde dos colaboradores em 2 anos;
Redução da taxa de tabagismo entre os colaboradores de 20,48% para 9,3%;
Redução do IMC de pelo menos 50% dos colaboradores acima do peso em 5 unidades de IMC;
Aumento da frequência de exames preventivos;
Melhoria da percepção dos colaboradores sobre a saúde e o bem-estar no trabalho.
Comunicação e Engajamento:
É fundamental comunicar o plano de ação para todos os colaboradores de forma clara, concisa e engajadora.
Utilizar diversos canais de comunicação, como e-mail, intranet, redes sociais, cartazes e eventos.
7. Considerações finais#
O estudo em questão fornece insights valiosos sobre os fatores que influenciam o custo da saúde na empresa. A metodologia rigorosa e os resultados robustos demonstram a relação entre tabagismo, IMC elevado e custo da saúde, destacando a importância da promoção da saúde e do bem-estar dos colaboradores para o controle dos custos na empresa. A implementação do plano de ação proposto pode gerar benefícios financeiros e de saúde significativos para a empresa e seus colaboradores.
7.1 Limitações#
Possibilidade de outros fatores não considerados influenciarem o custo da saúde.
O modelo de regressão linear múltipla apresenta algumas limitações, o que pode afetar a precisão das estimativas:
Heterocedasticidade
Não normalidade dos resíduos
7.2 Próximos Passos#
Os próximos passos para este projeto podem incluir:
Implementação das ações preventivas sugeridas para diminuir o custo do plano de saúde.
Monitoramento contínuo dos custos do plano de saúde e revisão periódica da análise para ajustes necessários.
Exploração de outras técnicas de análise de dados para obter insights adicionais.
7.3 Agradecimentos#
Gostaria de expressar minha sincera gratidão à escola de dados Preditiva Analytics Treinamentos Ltda por disponibilizar os dados e o contexto de negócios fictícios utilizados neste estudo. Sua generosa contribuição foi fundamental para o desenvolvimento deste trabalho e enriqueceu significativamente minha compreensão do assunto. Agradeço profundamente pela parceria e apoio durante todo o processo.
Links Úteis#
GASPAR, Juliano de Souza et al. Introdução à análise de dados em saúde com Python. In: Introdução à análise de dados em saúde com Python. 2023. Disponível em: https://repositorio.ufmg.br/handle/1843/55554. Acesso em: 04 mar. 2024.
MINISTÉRIO DA SAÚDE. Cartilha Tabagismo 2023. 2023. Disponível em: https://www.saude.mg.gov.br/images/2023/Tabagismo 2023/cartilha-tabagismo-2023 1.pdf. Acesso em: 07 mai. 2024.
MINISTÉRIO DA SAÚDE. Tabagismo. 2023. Disponível em: https://www.saude.mg.gov.br/tabagismo. Acesso em: 07 mai. 2024.
MINISTÉRIO DA SAÚDE. Vigitel Brasil 2006-2023 : tabagismo e consumo abusivo de álcool. Disponível em: https://www.gov.br/saude/pt-br/centrais-de-conteudo/publicacoes/svsa/vigitel/vigitel-brasil-2006-2023-tabagismo-e-consumo-abusivo-de-alcool/view. Acesso em: 07 mai. 2024.
XANCHÃO, Raphael Costa; CRUZ, Frederico RB. Construção de intervalos de confiança via bootstrap. 2010. Disponível em: https://www.est.ufmg.br/ftp/fcruz/pub/bootic.pdf. Acesso em: 07 mai. 2024.